There is a noisy market in queue management software. Most of it is marketing skin over the same five-or-six capabilities, and the operator buying for the first time has very little signal to distinguish a serious system from a re-skinned ticket dispenser with a web UI bolted on. A useful evaluation framework cuts through that noise by asking what the operator actually has to live with for the next five years.
The four questions that actually separate serious systems from window-dressing
The questions worth asking are not the ones on the vendor brochure. They are these:
- 1Where does the data live? A serious queue management system either runs on-premises inside the operator's perimeter or runs in a region the operator's regulator accepts, with a clear data-residency contract. If the vendor cannot answer this without a sales engineer on the call, that is the answer.
- 2What is the failure mode when the network drops? Branch operators lose connectivity. Hospitals lose connectivity. Government offices lose connectivity. A serious QMS keeps the local counter calling, the local kiosk dispensing, and the local display updating even when the central server is unreachable, and reconciles when the link comes back. Anything cloud-only fails the moment the link drops, which is a worse customer experience than the paper ticket it replaced.
- 3What is the integration surface? A queue management system that cannot talk to the operator's CRM, the appointment-booking system, the digital signage, the customer-feedback survey, and the analytics warehouse is a silo. Operators end up reconciling data manually and the cockpit telemetry becomes untrustworthy. A serious system exposes a documented REST or webhook API and ships with adapters for the common integration partners.
- 4Who owns the source if the vendor disappears? This is the question that is almost never asked at procurement and almost always asked three years later when the vendor pivots or gets acquired. The operator wants either a source-escrow clause, a perpetual license posture, or, in our case, the option to take the repository at the end of the engagement and run it themselves.
Vendors that have credible answers to all four are the shortlist. Vendors that dodge two or three are not.
The capability checklist that actually matters
Under the four questions above, the operationally relevant capabilities cluster into roughly six areas:
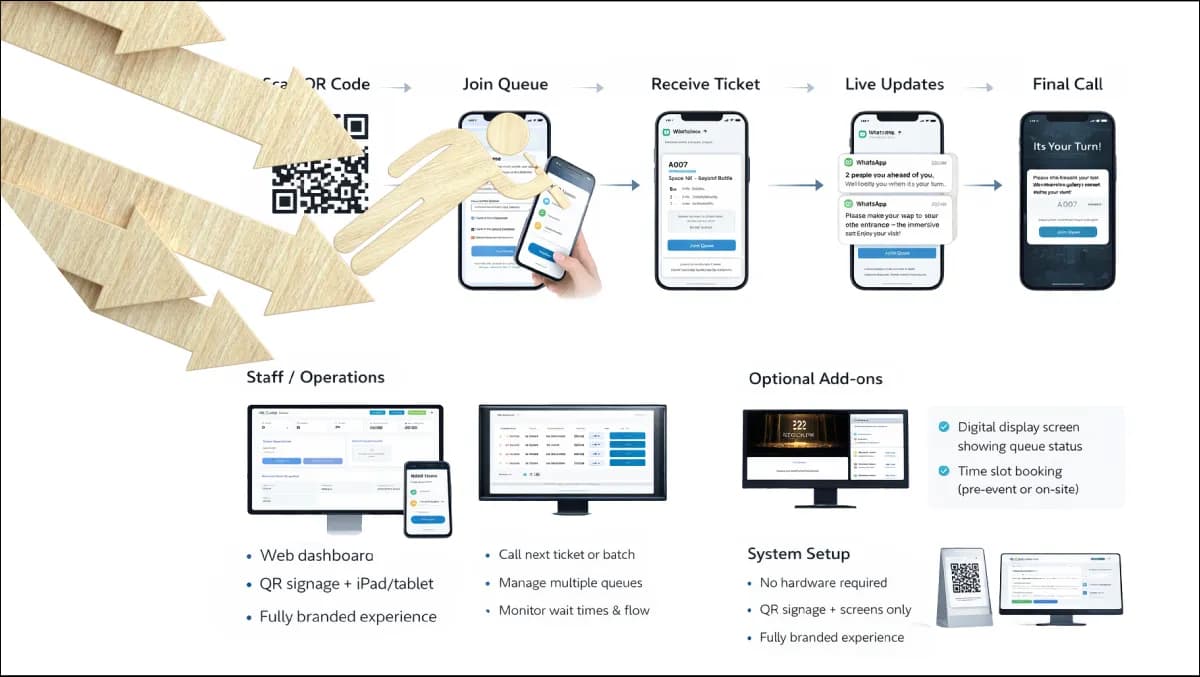
- Multi-channel join — a serious system lets the customer join the queue via on-site kiosk, mobile virtual-queue link, online appointment, or staff-side check-in, with all four writing to the same back-end. Mixed-channel reporting (how many customers came via kiosk vs mobile this month) is a critical analytics input.
- Real-time cockpit — operator-side dashboard with live queue depth, average wait, service rate per counter, exception flags, and the ability to retask staff on the fly. The cockpit has to be usable by a supervisor on a 12-hour shift, not designed for a product demo.
- Notifications layer — SMS, app push, WhatsApp, email, whichever channels the operator's customers actually use. Bilingual or multilingual notifications keyed to the customer's preferred-language field.
- Integration adapters — at minimum, an REST API and webhook framework, ideally with pre-built adapters for HL7 / FHIR (healthcare), the operator's CRM (Salesforce, Dynamics, HubSpot), the operator's digital signage system, and the analytics warehouse.
- Multilingual UI — the operator-facing surfaces and the customer-facing surfaces both need to ship in the operator's working languages. English and Arabic with full RTL as a production baseline is the right default for most regions we ship into; French, Spanish, German, Portuguese, Italian, Dutch, Turkish, Urdu, Hindi and others come per engagement.
- Audit trail and data-subject controls — every queue interaction logged with a timestamp and an actor. Data-subject delete capability. Retention policy configurable by the operator. This is not optional under GDPR, PDPL, the federal UAE health-data framework, or any of the other modern data-protection regimes.
A capability that does not appear on this list — chatbot integration, AI wait-time prediction, virtual concierge avatars — may or may not be useful. They are nice-to-haves. The six above are the floor.
What "best" actually means by operator type
There is no single best queue management system. There is a best fit per operator type.
- Banking and financial services — prioritise integration with the core banking system, KYC and identity verification at check-in, and bilingual or multilingual support for international branches. The cockpit needs to handle private-banking lounge flows alongside retail-branch flows.
- Healthcare — prioritise HL7 / FHIR integration, insurance pre-authorisation handling, bilingual EN/AR (in regions where that is the operating norm) or other locale combinations per engagement, and a cockpit designed for the nurse-station workflow rather than the bank-teller workflow.
- Government services — prioritise high-throughput multi-service flows, identity-system integration (national ID, citizen portal), accessibility (WCAG-conformant kiosks), and a strong audit trail for citizen-service compliance.
- Retail — prioritise self-service kiosks at the door, mobile virtual queueing so the customer can browse while waiting, and integration with the POS so the cashier already has the customer context when called.
- Telecom and utilities — prioritise integration with the CRM and the billing system, customer-history context at the counter, and the ability to handle complex multi-step services (number-port, contract upgrade, equipment swap) without the customer being bounced between counters.
The vendor that is best for a 1,200-patient hospital outpatient floor is not the vendor that is best for a 6-branch retail rollout. Procurement teams who insist on a single "best" tool across the entire operator end up either buying for the lowest-common-denominator workflow or buying twice.
How GLARUS positions in this evaluation
GLARUS — the queue management ecosystem at the heart of /solutions/queue-management-system — is currently in production at 1,247+ branches across 40+ countries. The product line covers the full ecosystem: queue management, virtual queue, online appointment, self-service kiosk, wayfinding, and customer feedback. It deploys sovereign on-premises by default, ships with English and Arabic full-RTL as a production baseline, integrates against HL7 / FHIR / REST / webhook / CRM adapters as standard scope, and the engagement model gives the operator the repository, the license, and the deploy keys at the end of a 90-day exit window.
What the procurement process should look like
The procurement processes that produce good queue management deployments tend to follow a consistent shape. The operator's procurement team puts together a long-list from desk research and analyst reports — typically 8 to 12 vendors. The operations team and the IT team filter that down to a shortlist of 3 to 5 based on the four-question framework above. The shortlisted vendors get invited to demo, ideally against the operator's actual workflow (not a generic demo script). The demos are followed by reference calls — actual operator customers in similar verticals, not press releases. The final decision usually rests on three things: how the vendor handled the demo against the operator's awkward edge-cases, what the references actually said when asked the harder questions, and the commercial posture (fixed-fee vs T&M, exit terms, escrow, IP ownership).
The procurements that go wrong usually skip one of those steps. The operators who run a slick demo without testing the awkward edge-cases end up surprised at go-live. The operators who skip the reference calls miss the operational reality of what the vendor's product is actually like in production. The operators who do not negotiate the commercial posture properly end up locked into a relationship that costs more than the original sticker price by year three.
Pilot, then scale
A serious queue management deployment runs as a phased programme rather than a big-bang rollout. The shape we recommend, and the shape we run on every engagement:
- Discovery (fixed-fee, 2 to 4 weeks) — workshops with operations, IT, compliance. Current-state map. Target architecture. Fixed-fee Build estimate.
- Build (8 to 16 weeks) — the technical integration, the cockpit configuration, the bilingual or multilingual UI work, the audit-logging policy, the kiosk staging.
- Pilot (2 to 4 weeks) — one site running under supervision with a Zeour engineer on-site half-time. The pilot is where the awkward edge-cases that did not surface in Discovery actually surface.
- Rollout (variable) — phased extension to the rest of the estate, typically in waves of 5 to 20 sites.
- Operate — ongoing on a Care Plan tier, or operator self-sufficiency after the 90-day exit window.
The big-bang rollouts — "deploy to 200 branches in one weekend" — are the ones that produce the procurement-team horror stories. Phased pilots produce calm go-lives.
Whether that shape is the right fit for a given operator is a conversation, not a brochure decision. The shortlist worth running is the one that answers the four questions above with specifics, not the one with the glossiest landing page.